APROXiMACiONES A LA IMPLEMENTACIÓN DE DSM
La memoria compartida distribuida se implementa utilizando uno de los siguientes métodos o bien una combinación de ellos, hardware especializado, memoria virtual paginada convencional o middleware:
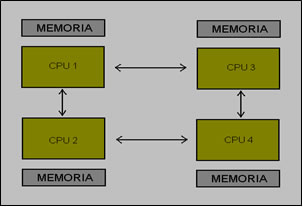
Hardware: las arquitecturas multiprocesador de memoria compartida basadas en una arquitectura NUMA (por ejemplo, Dash [Lenoski y otros 1992] y PLUS [Bisiani y Ravishankar 1990] se basan en hardware especializado para proporcionar a los procesadores una visión consistente de la memoria compartida. Gestionan las instrucciones de acceso a memoria LOAD y STORE de forma que se comuniquen con la memoria remota y los módulos de caché según sea necesario para almacenar y obtener datos. Esta comunicación se realiza sobre sistemas de interconexión de alta velocidad similares a una red. El prototipo del multiprocesador Dash tiene 64 nodos; conectados mediante una arquitectura NUMA.
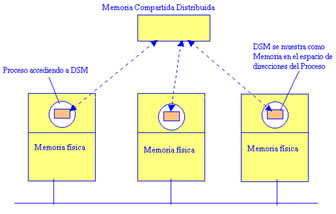
Memoria virtual paginada: muchos sistemas, incluyendo Ivy [Li y Hudak 1989], Munin [Carter y otros 1991], Mirage [Fleisch y Popek 1989], Clouds [Dasgupta y otros 1991], Choices [Sane y otros 1990], COOL (Lea y otros 1993] y Mether [Minnich y Farber 1989], implementan DSM como una región de memoria virtual que ocupa el mismo rango de direcciones en el espacio de direcciones de cada proceso participante. Este tipo de implementación normalmente sólo es factible sobre una colección de computadores homogéneos con formatos de datos y de paginación comunes.
Middleware: algunos lenguajes del tipo de Orca [Bal y otros 1990] y middleware como Linda [Carriero y Gelernter 1989] junto con sus derivados JavaSpaces y TSpaces [Wyckoff y otros 1998] proporcionan DSM sin necesidad de soporte hardware o de paginación, de una forma independiente de la plataforma. En este tipo de implementación, la computación se implementa mediante la comunicación entre instancias del nivel de soporte de usuario en los clientes y los servidores. Los procesos realizan llamadas a este nivel cuando acceden a datos en DSM. Las instancias de este nivel en los diferentes computadores acceden a los datos locales y se intercambian información siempre que sea necesario para el mantenimiento de la consistencia.
Con soporte hardware, se pueden utilizar técnicas software de alto nivel para minimizar la cantidad de comunicación entre componentes de una implementación DSM.
La aproximación basada en páginas tiene la ventaja de que no impone una estructura particular en la DSM, que se muestra como una secuencia de bytes. Inicialmente permite que los programas diseñados para multiprocesadores de memoria compartida se ejecuten en computadores sin memoria compartida, con muy poca o ninguna adaptación. Los micronúcleos como Mach y Chorus proporcionan soporte nativo para DSM (y otras abstracciones de memoria). Actualmente, los sistemas DSM basados en páginas son implementados en su mayor parte en el nivel de usuario debido a su mayor flexibilidad. La implementación utiliza el soporte del núcleo para los manejadores de fallos de las páginas de nivel de usuario. UNIX y algunas variantes de Windows proporcionan esta posibilidad. Los microprocesadores con espacios de direcciones de 64-bits amplían el ámbito de los sistemas DSM basados en páginas mediante la relajación de las restricciones en la gestión del espacio de direcciones [Bartoli y otros 1993].
La implementación de una memoria distribuida consta de:
· Acceso compartido a la memoria à comunicación Inter-procesos.
· Ningún procesador puede acceder directamente a la memoria de otro procesador à NORMA (NO Remote Memory Access) Systems.
· Los procesadores hacen referencia a su propia memoria local. Hay que aumentar software para que, cuando un procesador haga referencia a una página remota, esta página sea recuperada.
· El espacio de direccionamiento común es particionado en pedazos.
· Cada pedazo es situado en una estación.
· Cuando un procesador hace referencia a una pagina no local à "trap" (page fault).